Strategic Listening: A Guide to Python Social Media Analysis
Listening is everything—especially when it comes to effective marketing and product design. Gain key market insights from social media data using sentiment analysis and topic modeling in Python.

Listening is everything—especially when it comes to effective marketing and product design. Gain key market insights from social media data using sentiment analysis and topic modeling in Python.

Federico is an expert Python developer and data scientist who has worked at Facebook, implementing deep learning models. He is a university lecturer, and his PhD research focuses on natural language processing and machine learning.
Expertise
PREVIOUSLY AT

With a global penetration rate of 58.4%, social media provides a wealth of opinions, ideas, and discussions shared daily. This data offers rich insights into the most important and popular conversation topics among users.
In marketing, social media analysis can help companies understand and leverage consumer behavior. Two common, practical methods are:
- Topic modeling, which answers the question, “What conversation topics do users speak about?”
- Sentiment analysis, which answers the question, “How positively or negatively are users speaking about a topic?”
In this article, we use Python for social media data analysis and demonstrate how to gather vital market information, extract actionable feedback, and identify the product features that matter most to clients.
Social Media Analysis Case Study: Smartwatches on Reddit
To prove the utility of social media analysis, let’s perform a product analysis of various smartwatches using Reddit data and Python. Python is a strong choice for data science projects, and it offers many libraries that facilitate the implementation of the machine learning (ML) and natural language processing (NLP) models that we will use.
This analysis uses Reddit data (as opposed to data from Twitter, Facebook, or Instagram) because Reddit is the second most trusted social media platform for news and information, according to the American Press Institute. In addition, Reddit's subforum organization produces “subreddits” where users recommend and criticize specific products; its structure is ideal for product-centered data analysis.
First we use sentiment analysis to compare user opinions on popular smartwatch brands to discover which products are viewed most positively. Then, we use topic modeling to narrow in on specific smartwatch attributes that users frequently discuss. Though our example is specific, you can apply the same analysis to any other product or service.
Preparing Sample Reddit Data
The data set for this example contains the title of the post, the text of the post, and the text of all comments for the most recent 100 posts made in the r/smartwatch subreddit. Our dataset contains the most recent 100 complete discussions of the product, including users' experiences, recommendations about products, and their pros and cons.
To collect this information from Reddit, we will use PRAW, the Python Reddit API Wrapper. First, create a client ID and secret token on Reddit using the OAuth2 guide. Next, follow the official PRAW tutorials on downloading post comments and getting post URLs.
Sentiment Analysis: Identifying Leading Products
To identify leading products, we can examine the positive and negative comments users make about certain brands by applying sentiment analysis to our text corpus. Sentiment analysis models are NLP tools that categorize texts as positive or negative based on their words and phrases. There is a wide variety of possible models, ranging from simple counters of positive and negative words to deep neural networks.
We will use VADER for our example, because it is designed to optimize results for short texts from social networks by using lexicons and rule-based algorithms. In other words, VADER performs well on data sets like the one we are analyzing.
Use the Python ML notebook of your choice (for example, Jupyter) to analyze this data set. We install VADER using pip:
pip install vaderSentiment
First, we add three new columns to our data set: the compound sentiment values for the post title, post text, and comment text. To do this, iterate over each text and apply VADER's polarity_scores method, which takes a string as input and returns a dictionary with four scores: positivity, negativity, neutrality, and compound.
For our purposes, we’ll use only the compound score—the overall sentiment based on the first three scores, rated on a normalized scale from -1 to 1 inclusive, where -1 is the most negative and 1 is the most positive—in order to characterize the sentiment of a text with a single numerical value:
# Import VADER and pandas
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
import pandas as pd
analyzer = SentimentIntensityAnalyzer()
# Load data
data = pd.read_json("./sample_data/data.json", lines=True)
# Initialize lists to store sentiment values
title_compound = []
text_compound = []
comment_text_compound = []
for title,text,comment_text in zip(data.Title, data.Text, data.Comment_text):
title_compound.append(analyzer.polarity_scores(title)["compound"])
text_compound.append(analyzer.polarity_scores(text)["compound"])
comment_text_compound.append(analyzer.polarity_scores(comment_text["compound"])
# Add the new columns with the sentiment
data["title_compound"] = title_compound
data["text_compound"] = text_compound
data["comment_text_compound"] = comment_text_compound
Next, we want to catalog the texts by product and brand; this allows us to determine the sentiment scores associated with specific smartwatches. To do this, we designate a list of product lines we want to analyze, then we verify which products are mentioned in each text:
list_of_products = ["samsung", "apple", "xiaomi", "huawei", "amazfit", "oneplus"]
for column in ["Title","Text","Comment_text"]:
for product in list_of_products:
l = []
for text in data[column]:
l.append(product in text.lower())
data["{}_{}".format(column,product)] = l
Certain texts may mention multiple products (for example, a single comment might compare two smartwatches). We can proceed in one of two ways:
- We can discard those texts.
- We can split those texts using NLP techniques. (In this case, we would assign a part of the text to each product.)
For the sake of code clarity and simplicity, our analysis discards those texts.
Sentiment Analysis Results
Now we are able to examine our data and determine the average sentiment associated with various smartwatch brands, as expressed by users:
for product in list_of_products:
mean = pd.concat([data[data["Title_{}".format(product)]].title_compound,
data[data["Text_{}".format(product)]].text_compound,
data[data["Comment_text_{}".format(product)]].comment_text_compound]).mean()
print("{}: {})".format(product,mean))
We observe the following results:
Smartwatch | Samsung | Apple | Xiaomi | Huawei | Amazfit | OnePlus |
|---|---|---|---|---|---|---|
Sentiment Compound Score (Avg.) | 0.4939 | 0.5349 | 0.6462 | 0.4304 | 0.3978 | 0.8413 |
Our analysis reveals valuable market information. For example, users from our data set have a more positive sentiment regarding the OnePlus smartwatch over the other smartwatches.
Beyond considering average sentiment, businesses should also consider the factors affecting these scores: What do users love or hate about each brand? We can use topic modeling to dive deeper into our existing analysis and produce actionable feedback on products and services.
Topic Modeling: Finding Important Product Attributes
Topic modeling is the branch of NLP that uses ML models to mathematically describe what a text is about. We will limit the scope of our discussion to classical NLP topic modeling approaches, though there are recent advances taking place using transformers, such as BERTopic.
There are many topic modeling algorithms, including non-negative matrix factorization (NMF), sparse principal components analysis (sparse PCA), and latent dirichlet allocation (LDA). These ML models use a matrix as input then reduce the dimensionality of the data. The input matrix is structured such that:
- Each column represents a word.
- Each row represents a text.
- Each cell represents the frequency of each word in each text.
These are all unsupervised models that can be used for topic decomposition. The NMF model is commonly used for social media analysis, and is the one we will use for our example, because it allows us to obtain easily interpretable results. It produces an output matrix such that:
- Each column represents a topic.
- Each row represents a text.
- Each cell represents the degree to which a text discusses a specific topic.
Our workflow follows this process:
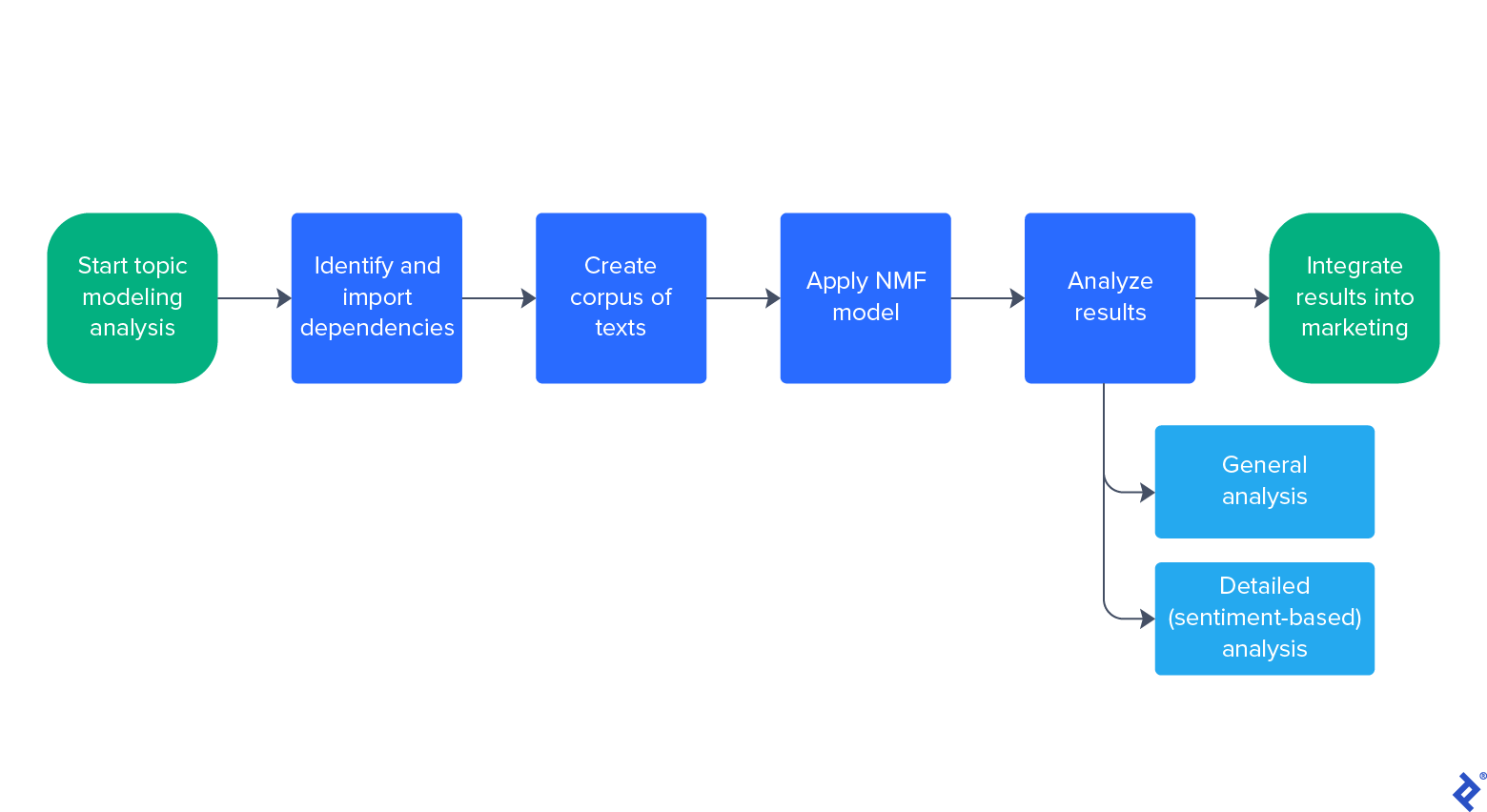
First, we'll apply our NMF model to analyze general topics of interest, and then we'll narrow in on positive and negative topics.
Analyzing General Topics of Interest
We'll look at topics for the OnePlus smartwatch, since it had the highest compound sentiment score. Let's import the required packages providing NMF functionality and common stop words to filter from our text:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.decomposition import NMF
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
Now, let's create a list with the corpus of texts we will use. We use the scikit-learn ML library's CountVectorizer and TfidfTransformer functions to generate our input matrix:
product = "oneplus"
corpus = pd.concat([data[data["Title_{}".format(product)]].Title,
data[data["Text_{}".format(product)]].Text,
data[data["Comment_text_{}".format(product)]].Comment_text]).tolist()
count_vect = CountVectorizer(stop_words=stopwords.words('english'), lowercase=True)
x_counts = count_vect.fit_transform(corpus)
feature_names = count_vect.get_feature_names_out()
tfidf_transformer = TfidfTransformer()
x_tfidf = tfidf_transformer.fit_transform(x_counts)
(Note that details about handling n-grams—i.e., alternative spellings and usage such as "one plus"—can be found in my previous article on topic modeling.)
We are ready to apply the NMF model and find the latent topics in our data. Like other dimensionality reduction methods, NMF needs the total number of topics to be set as a parameter (dimension). Here, we choose a 10-topic dimensionality reduction for simplicity, but you could test different values to see what number of topics yields the best unsupervised learning result. Try setting dimension to maximize metrics such as the silhouette coefficient or the elbow method. We also set a random state for reproducibility:
import numpy as np
dimension = 10
nmf = NMF(n_components = dimension, random_state = 42)
nmf_array = nmf.fit_transform(x_tfidf)
components = [nmf.components_[i] for i in range(len(nmf.components_))]
features = count_vect.get_feature_names_out()
important_words = [sorted(features, key = lambda x: components[j][np.where(features==x)], reverse = True) for j in range(len(components))]
important_words contains lists of words, where each list represents one topic and the words are ordered within a topic by importance. It includes a combination of meaningful and “garbage” topics; this is a common result in topic modeling because it is difficult for the algorithm to successfully cluster all texts into just a few topics.
Examining the important_words output, we notice meaningful topics around words like “budget” or “charge”, which points to features that matter to users when discussing OnePlus smartwatches:
['charge', 'battery', 'watch', 'best', 'range', 'days', 'life', 'android', 'bet', 'connectivity']
['budget', 'price', 'euros', 'buying', 'purchase', 'quality', 'tag', 'worth', 'smartwatch', '100']
Since our sentiment analysis produced a high compound score for OnePlus, we might assume that this means it has a lower cost or better battery life compared to other brands. However, at this point, we don't know whether users view these factors positively or negatively, so let's conduct an in-depth analysis to get tangible answers.
Analyzing Positive and Negative Topics
Our more detailed analysis uses the same concepts as our general analysis, applied separately to positive and negative texts. We will uncover which factors users point to when speaking positively—or negatively—about a product.
Let’s do this for the Samsung smartwatch. We will use the same pipeline but with a different corpus:
- We create a list of positive texts that have a compound score greater than 0.8.
- We create a list of negative texts that have a compound score less than 0.
These numbers were chosen to select the top 20% of positive texts scores (>0.8) and top 20% of negative texts scores (<0), and produce the strongest results for our smartwatch sentiment analysis:
# First the negative texts.
product = "samsung"
corpus_negative = pd.concat([data[(data["Title_{}".format(product)]) & (data.title_compound < 0)].Title,
data[(data["Text_{}".format(product)]) & (data.text_compound < 0)].Text,
data[(data["Comment_text_{}".format(product)]) & (data.comment_text_compound < 0)].Comment_text]).tolist()
# Now the positive texts.
corpus_positive = pd.concat([data[(data["Title_{}".format(product)]) & (data.title_compound > 0.8)].Title,
data[(data["Text_{}".format(product)]) & (data.text_compound > 0.8)].Text,
data[(data["Comment_text_{}".format(product)]) & (data.comment_text_compound > 0.8)].Comment_text]).tolist()
print(corpus_negative)
print(corpus_positive)
We can repeat the same method of topic modeling that we used for general topics of interest to reveal the positive and negative topics. Our results now provide much more specific marketing information: For example, our model's negative corpus output includes a topic about the accuracy of burned calories, while the positive output is about navigation/GPS and health indicators like pulse rate and blood oxygen levels. Finally, we have actionable feedback on aspects of the smartwatch that the users love and areas where the product has room for improvement.

wordcloud LibraryTo amplify your data findings, I'd recommend creating a word cloud or another similar visualization of the important topics identified in our tutorial.
Limitless Product Insights With Social Media Analysis
Through our analysis, we understand what users think of a target product and those of its competitors, what users love about top brands, and what may be improved for better product design. Public social media data analysis allows you to make informed decisions regarding business priorities and enhance overall user satisfaction. Incorporate social media analysis into your next product cycle for improved marketing campaigns and product design—because listening is everything.
The editorial team of the Toptal Engineering Blog extends its gratitude to Daniel Rubio for reviewing the code samples and other technical content presented in this article.
Further Reading on the Toptal Blog:
- Data Mining for Predictive Social Network Analysis
- Ensemble Methods: Elegant Techniques to Produce Improved Machine Learning Results
- Getting Started With TensorFlow: A Machine Learning Tutorial
- Adversarial Machine Learning: How to Attack and Defend ML Models
- Mining for Data Clusters: Social Network Analysis With R and Gephi
Understanding the basics
Can Python be used for data analysis?
Yes, Python is a popular language for data analysis. The Python developer community is strong, and there are many Python libraries available for machine learning and natural language processing.
Why is analyzing social media important?
Social media posts offer plenty of insights that can be used for marketing and product design purposes. Analyzing user opinions on products provides companies with actionable, data-driven feedback that can elevate a brand above its competitors.
Why do we use topic modeling?
Topic modeling uses unsupervised machine learning to identify topics within a text. For example, in this article we use topic modeling to determine a product’s important features (topics) from users’ social media posts (texts).
Is Python good for sentiment analysis?
Yes, Python is a strong choice for sentiment analysis due to its many relevant libraries. The VADER library provides resources for sentiment analysis specific to social media, and the NLTK library provides text tools such as a list of stop words.
Federico Albanese
Buenos Aires, Argentina
Member since January 9, 2019
About the author
Federico is an expert Python developer and data scientist who has worked at Facebook, implementing deep learning models. He is a university lecturer, and his PhD research focuses on natural language processing and machine learning.
Expertise
PREVIOUSLY AT